





What Is Agentic RAG
Agentic RAG goes beyond simple retrieval by letting AI think, plan, and search across multiple sources. Learn how it works, its use cases, pros and cons, and what it means for your business.
Saturncube
22 May 2026
Most people who follow AI closely have heard of RAG by now. Retrieval Augmented Generation, which lets an AI model pull in external information before it answers a question, became one of the most widely used techniques for building smarter, more accurate AI systems over the last couple of years. It solved a real problem: AI models trained on fixed data get outdated, make things up, and cannot access your private business knowledge. RAG fixed that by giving AI a way to look things up before responding.
But RAG on its own has limits. And those limits become very obvious when you try to use it for anything genuinely complex. Agentic RAG is the next step forward, and understanding what it is and how it works matters quite a bit for anyone building or evaluating AI systems today. Ready to implement Agentic RAG in your business? Our AI Software Development team specializes in building RAG systems with agentic capabilities.

What Standard RAG Actually Does
RAG stands for Retrieval Augmented Generation. The idea is simple: before an AI generates a response, it fetches relevant information from an external source, database, or document store, and uses that fetched content to produce a more accurate, grounded answer.
Standard RAG works in a straight line. A user asks a question, the system searches a database for relevant content, retrieves the most relevant chunks of text, and passes them to the language model along with the original question. The model reads that retrieved context and generates a response based on it.
That is genuinely useful. A company can upload its internal documentation, product manuals, or policy files and build a system that answers questions using that content instead of making things up. It stays accurate as long as the database is updated.
The problem is that this process is single-step and linear. The system retrieves once, generates once, and stops. It does not check whether its answer is correct. It cannot go back for more information if the first retrieval was incomplete. It cannot break a complex question into parts and handle each one separately. For simple questions, that is fine. For anything complicated, it falls short quickly.
RAG Is Not One Thing Anymore
What many people do not realize is that RAG has evolved significantly. There are now many different types of RAG architectures being used and researched, each designed to handle different kinds of problems.
Some of the main types being used today include:
Agentic RAG sits at the center of this landscape because it can incorporate principles from many of the others. It is not just one variation - it is an architecture that treats retrieval as something to reason about, not just execute.

What Agentic RAG Actually Does Differently
Agentic RAG is what happens when you give the retrieval process a brain.
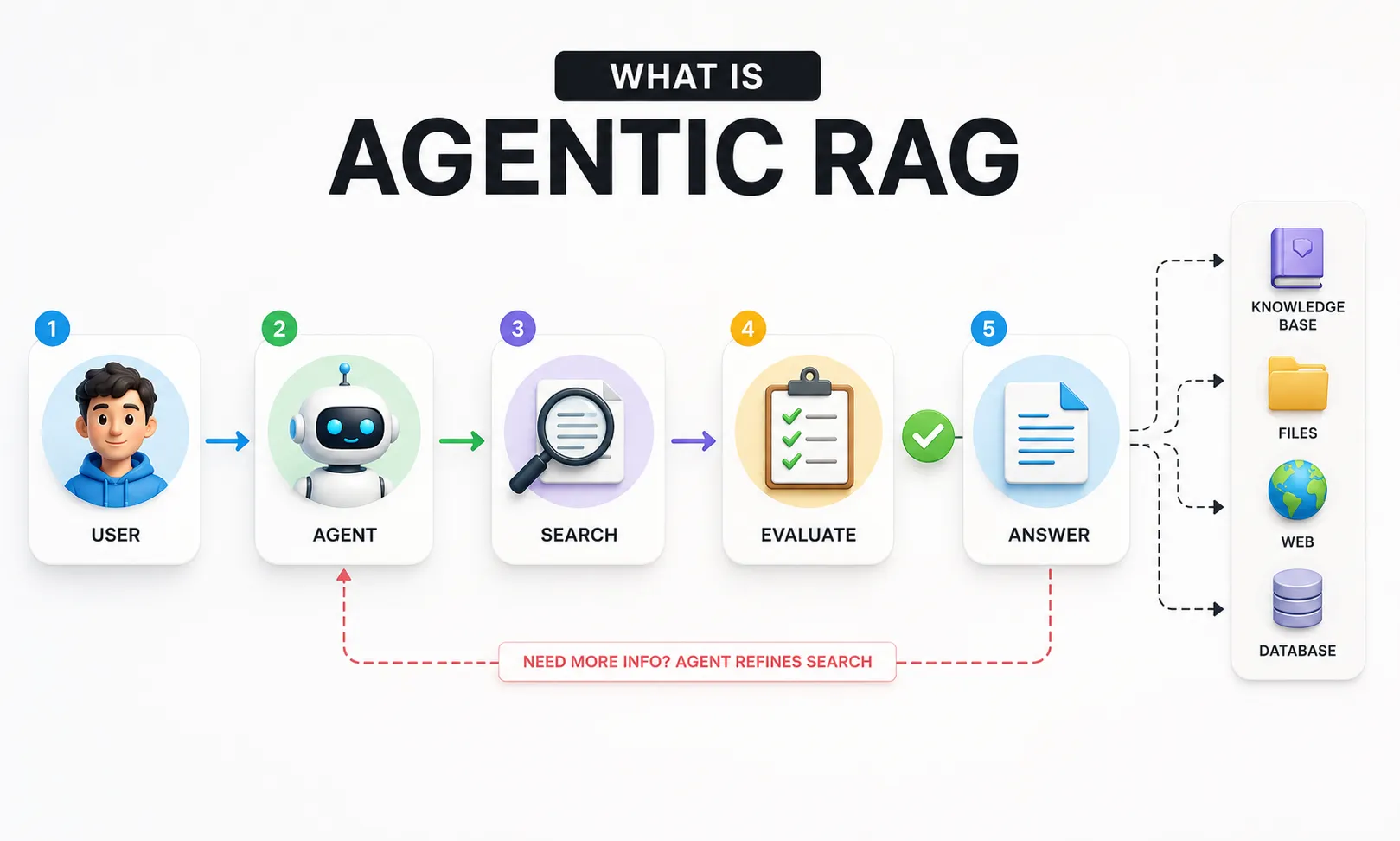
Instead of retrieving once and generating a response, an agentic RAG system thinks about what it needs, decides how to get it, searches multiple sources, evaluates whether what it found is actually useful, and loops back if the answer is not complete yet. As one way to think about it: agentic RAG acts like a researcher. It plans, searches, and uses tools instead of just retrieving once. It breaks tasks into steps, keeps evaluating results, and continues until it finds a good answer.
The architecture behind this is different from standard RAG in a meaningful way. A standard RAG system moves in one direction: query in, response out. An agentic RAG system is a loop. The query goes in, the agent decides which tools to use and in what order, retrieves from multiple sources simultaneously or in sequence, evaluates the results, and only generates the final answer when it has enough good information to do so reliably.
Those tools can include vector search engines across different collections, web search APIs, calculators, SQL databases, document parsers, or any other source that can return relevant information. The agent chooses which tools to use based on what the question actually needs.
The clearest way to see the difference between these two approaches is to put them next to each other on the dimensions that matter most in production.
Simple RAG | Agentic RAG | |
|---|---|---|
Retrieval steps | Once per query | Multiple, iterative |
Sources | Single database | Multiple sources and tool types |
Self-correction | No | Yes, validates before generating |
Complex query handling | Limited | Breaks into sub-tasks, handles each |
Response time | Fast | Slower, deeper |
Build complexity | Lower | Higher, requires orchestration |
Best for | FAQ bots, simple knowledge retrieval | Research, analysis, multi-document work |
Cost per query | Lower | Higher |
This table shows where each approach earns its place. Simple RAG is the right tool for straightforward, repetitive questions from a fixed knowledge base. Agentic RAG is the right tool when the question itself requires judgment, planning, and multiple sources to answer well.
Ready to Build Your AI Agent?
Our AI development team has built 50+ AI agents for businesses across healthcare, e-commerce, and SaaS. From concept to deployment, we handle everything.
Explore AI Development Services
Where Agentic RAG Is Being Used Today
The systems that benefit most from agentic RAG are the ones where single-step retrieval is clearly not enough. The strongest use cases right now include:
The Honest Tradeoffs: Pros and Cons
Agentic RAG is more capable than simple RAG, but it is not the right choice for every situation. Understanding the tradeoffs clearly helps businesses and developers choose the right architecture for the job.
Where agentic RAG genuinely excels:
Where the tradeoffs show up:
These are real tradeoffs, not reasons to avoid agentic RAG. They are reasons to choose it thoughtfully, for use cases where the added accuracy and capability justify the added complexity and cost.

What This Means for Businesses Building AI Systems
If your business is building or evaluating AI systems, the practical implication is straightforward. Match the architecture to the complexity of the questions your system needs to answer.
For a simple internal FAQ bot or a customer support tool handling repetitive questions from a fixed knowledge base, standard RAG is probably sufficient and the smarter economic choice. For anything that requires nuanced reasoning, multi-source lookup, or iterative validation, agentic RAG is the right foundation.
The teams that get this right tend to start with a clearly scoped use case, build the simplest system that solves it, and then move toward agentic architecture as the complexity of real-world usage makes it necessary. That approach produces better outcomes than designing the most sophisticated possible system before you have operational experience to guide the decisions.
Data quality matters more than model sophistication at every level of this stack. An agentic system working with well-organized, clean, consistently structured data will outperform a more complex system working with messy inputs. Getting the data layer right before adding architectural complexity is almost always the right order of operations.
At Saturncube Technologies, we have been building AI-powered software since 2014, including retrieval systems, AI agent development, and custom LLM integrations across healthcare, finance, SaaS, and e-commerce. Whether your starting point is a single well-scoped retrieval system or a full agentic architecture, our team can help you design and build something that fits your actual workflows rather than a theoretical framework.
If you want to understand which approach makes sense for the problems your business is trying to solve, talk to our team. We can help you move from concept to a working system.
Read More
Read more on our blog
Related Articles:
Agentic AI vs AI Agents: What Is the Difference and Why It Matters
AI Agents for Financial Services: What Banks Are Doing in 2026
How AI Agents Are Changing Online Shopping and Payments in 2026